Scrapebox – program mający w świecie SEO złą renomę, który “ramię w ramię” z XRumerem ma moc zarzucania internetu automatycznie wygenerowanym spamem. Chciałabym jednak przedstawić inne oblicze tego narzędzia.
Oprócz funkcji wykorzystywanych w podczas black hat SEO (nie chciałabym wchodzić tutaj w filozoficzne rozważania nad white, grey, black SEO), Scrapebox posiada wiele możliwości, które przyspieszają i usprawniają codziennie czynności, na przykład zarządzanie linkami czy chociażby przygotowywanie matrycy przekierowań.
Nie ukrywam, że Scrapebox jest jednym z moich ulubionych narzędzi, dlatego chciałabym przedstawić kilka funkcji, z których zdarza mi się korzystać. Zdaję sobie sprawę, że większość z tych funkcjonalności można odnaleźć w innych narzędziach lub wykonać po prostu innym sposobem.
1. Sprawdzanie indeksacji linków
Zdobywanie linków to jedna kwestia, inną sprawą jest monitoring ich indeksacji. Zdobyty link, który nie jest zaindeksowany nie przynosi nam (doraźnej) wartości. Warto w związku z tym kontrolować to, ile zdobytych linków się indeksuje. W dłuższej perspektywie czasu można oszacować ile linków średnio się indeksuje w określonym czasie i na tej podstawie planować działania, czy określać miejsca linków, które prawdopodobnie mogą się szybko zaindeksować (wymaga to jednak dłuższej obserwacji).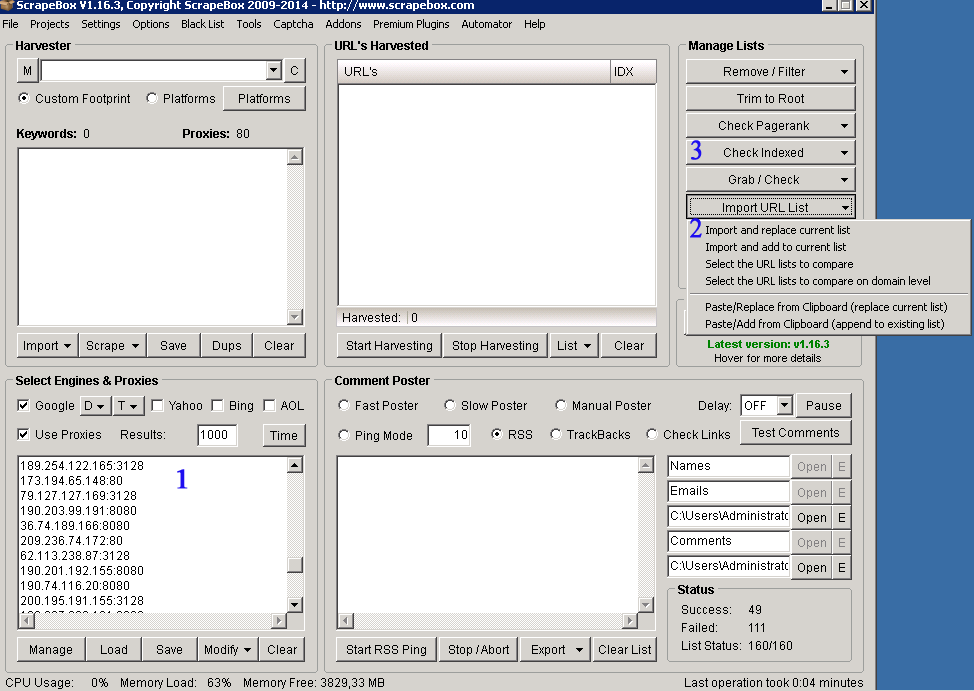
Podstawową kwestią jest posiadanie listy działających proxy, którymi zarządzamy w okienku 1. Następnie przygotowaną listę linków w formacie .txt wgrywamy za pomocą funkcji: Import URL List –> Import and replace current list. Wszystkie linki pojawią się w okienku URL’s Harvested. Po załadowaniu linków pozostaje nam wybranie opcji Check Indexed –> Google Indexed. Po wykonaniu tej operacji możemy eksportować linki do oddzielnych plików: z zaindeksowanymi oraz niezaindeksowanymi linkami (Export URL List –> dwie ostatnie opcje).
2. Sprawdzenie czy linki nie zostały skasowane
Zamieszczenie postu z linkiem do Klienta na jakimś forum czy w komentarzu na blogu to tylko część sukcesu. O pełnym sukcesie można mówić gdy link zostanie zaindeksowany z linkiem, który zamieszczaliśmy. Nierzadko się zdarza, że moderatorzy for usuwają linki/posty, które stanowią reklamę i nie wnoszą niczego do dyskusji lub blogerzy, którzy nie akceptują zamieszczonych komentarzy. Aby mieć pełen obraz wykonanych działań warto sprawdzić czy pod adresami URL zdobytych linków nadal znajdują się linki do Klienta.
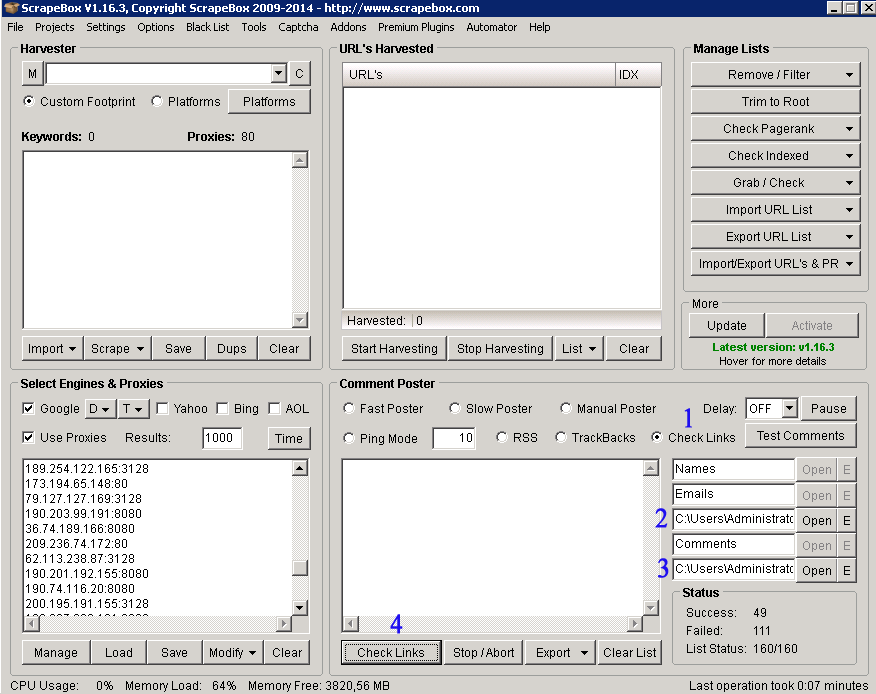
Pierwszym krokiem jest zaznaczenie opcji „Check Links”, która pozwala sprawdzić czy pod danym adresem jest szukana domena. Następnie, w kroku 2 wgrywamy wcześniej przygotowany plik .txt, który zawiera adresy szukanej domeny w postaci:
www.mojadomena.pl
mojadomena.pl
Krok trzeci, to miejsce w które wgrywamy listę zawierającą linki, które chcemy przeszukać (na przykład te, które udało nam się zdobyć). Po wgraniu obu plików klikamy „Check Links”, a po skończeniu przeszukiwania przez Scrapebox wystarczy eksportować linki z podziałem na „Found” (zawierające naszą domenę) i „Not Found”.
3. Pingowanie
Po wstępnej analizie zdobytych linków: oddzielenie linków zawierających pożądane odnośniki (np. do klienta) od tych, które ich nie zawierają (te nas nie bardzo interesują) oraz oddzielenie zaindeksowanych linków (z tych się możemy cieszyć) od tych niezaindeksowanych sporządzamy listę niezaindeksowanych URLi zawierających określone linki. Scrapebox posiada funkcję pingowania listy linków. Możemy to zrobić za pomocą wbudowanej funkcji lub za pomocą wtyczki Rapid Indexer (jeśli korzystamy z wtyczki, nie blokujemy innych procesów w Scrapebox). Do pingowania będziemy potrzebowali listy serwisów pingujących – Scrapebox udostępnia taką listę lub można poszukać własnej, na forach internetowych:)

W celu włączenia Indexera należy z puli dostępnych wtyczek (1) wybrać Rapid Indexer i po jej instalacji będzie dostępna w menu. Gdy przejdziemy do Rapid Indexera naszym oczom pojawi się powyższe okno – w drugim kroku wgrywamy listę linków przeznaczonych do indeksacji w formacji .txt, natomiast w kroku trzecim w wgrywamy listę serwisów pingujących i klikamy Start. Proces ten może zająć dość dużo czasu – w zależności jak duże listy zostaną wgrane.
4. Harvestowanie miejsc do linkowania
Ciągłe poszukiwanie miejsc do link buildingu do działanie, które jest bardzo istotne w całym procesie pozycjonowania strony, ale też czasochłonne. Scrapebox może również posłużyć do zbudowania bazy miejsc o określonej tematyce, w których możemy zostawić link. Do tego celu możemy wykorzystać funkcję harvestowania po footprintach (listy z footprintami można znaleźć w sieci). Należy mieć na uwadze, że w wyniku harvestowania otrzymujemy ogromne listy linków, które na pierwszy rzut oka mogą wydawać się bezużyteczne, ale po odpowiedniej obróbce można coś dla siebie znaleźć.

W pierwszym kroku wybieramy interesujący nas footprint, który będzie identyfikował grupę stron – na przykład „Powered by WordPress” itp. Kombinacje mogą być bardziej złożone, na przykład określające czy w title strony, URLu ma się pojawić określona fraza itp. W kroku drugim wybieramy grupę słów kluczowych, które mogą tematycznie określać szukane strony. Następnie klikamy „Start Harvest” i po kilku chwilach otrzymujemy w oknie URL’s Harvested bardzo dużą pulę linków, które wymagają odfiltrowania, a następnie możemy zabrać się za przeglądanie wyników.
Wstępny filtr:
- pozostawienie wyłącznie domen (opcja Trim to Root)
- usunięcie duplikatów (opcja Remove Duplicate Domains)
- w zależności od potrzeb np. usuniecie domen z rozszerzeniem .com (opcja Remove Domains Containing .com)
- sprawdzenie PR ( opcja Check Pagerank – można wybrać dla domeny lub dla adresu URL)
- zapisanie do pliku domen o określonym PR
Po takiej obróbce z tysięcy domen zostaje garstka, ale czasami na prawdę warto.
5. Opracowywanie listy linków
Posiadane listy różnych linków (przez siebie zdobytych, linki konkurencji, analiza linków przy usuwaniu filtra, itp.) wymagają wstępnego opracowania. Jeśli są to rozbudowane linków konieczna jest jak największa automatyzacja, która za pomocą kilku kliknięć pozwoli odfiltrować zbędne dane. Scrapebox posiada wiele użytecznych opcji, które są wbudowane w panelu bocznym.
Funkcje:
Trim to Root – skraca URL do domeny
Remove Duplicate URL’s/ Domains – usuwa duplikaty
Remove URL’s Containing/Not Containing – możemy pozbyć się adresów z określonym TLD, możemy usunąć konkretne katalogi itp.
Remove URL’s (Not) Containing Entries From – możemy z listy linków usunąć linki zawarte na innej liście – na przykład podczas analizy linków przy usuwaniu linków możemy usunąć z listy linków własne strony zapleczowe
Remove URL’s with the Extensions – z listy linków możemy przykładowo usunąć pliki tekstowe z różnymi rozszerzeniami

6. Sprawdzenie czy linki działają
Inną funkcją, którą można wykorzystać podczas analizy linków podczas usuwania filtra na stronie jest sprawdzenie czy linki działają. Można to sprawdzić za pomocą wtyczki Alive Check. Po wgraniu listy linków możemy pobrać 2 listy linków; “alive” – te podlegają dalszej analizie oraz “dead” – niedziałające, nie wiadomo co się pod nimi kryje.
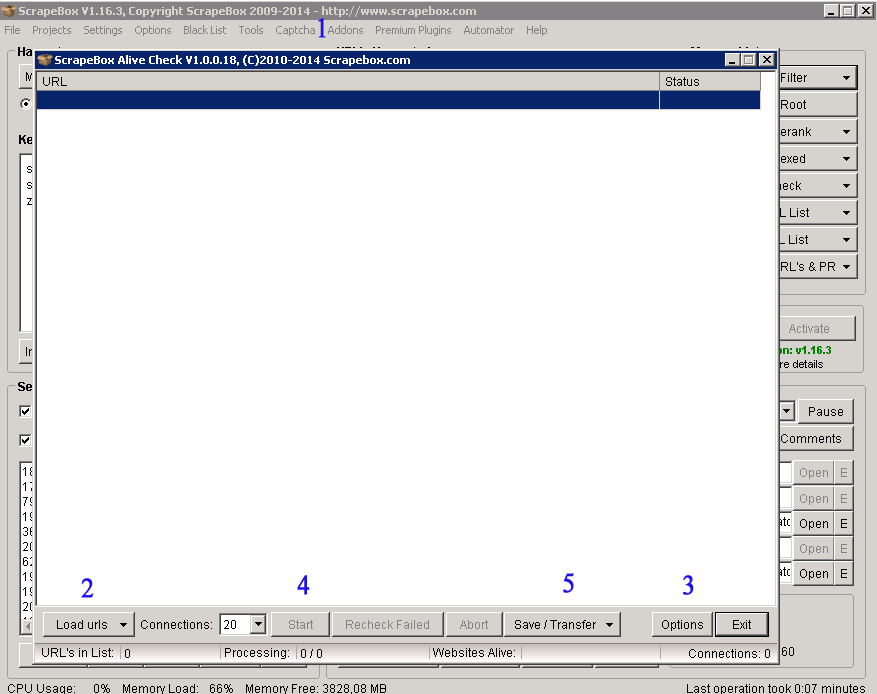
Z listy dostępnych wtyczek musimy zainstalować Alive Check, która później będzie dostępna w menu Addons. Po jej włączeniu ukaż się powyższe okno: w kroku drugim wgrywamy listę linków w formacie .txt, które chcemy przetestować. W opcjach wtyczki (3) możemy określić status, na którego podstawie będzie określane czy link działa (standardowo jest status 200). Następnie klikamy start, a po sprawdzeniu wszystkich linków możemy je zapisać w podziale na „alive” i „dead”.
7. Generowanie listy linków z sitemapy
Z tej funkcji Scrapeboxa zdarzała mi się korzystać podczas przygotowywania przykładowo przekierowań 301 ze starych adresów na nowe. Za pomocą wtyczki Sitemap Scraper możemy z już istniejącej sitemapy wygenerować listę linków.

Po zainstalowaniu wtyczki Sitemap Scraper i jej włączeniu otrzymujemy powyższe okno. W kroku pierwszym wgrywamy plik zawierający adres sitemapy strony: www.domena.pl/sitemap.xml, a następnie klikamy Start. W zależności od wielkości strony po kilku chwilach otrzymujemy listę wszystkich adresów URL zawartych w obrębie strony.
Warto mieć na uwadze, że analizując dane “przemielone” przez Scrapebox należy zachować rezerwę dotyczącą wyników z narzędzia. Zdarza się bowiem, że narzędzie wskazuje na brak indeksacji linka, który po site:domena.pl jest zaindeksowany (i odwrotnie) lub określa, że pod adresem URL dany link nie został odnaleziony. Wydaje mi się, że przy pracy z dużą liczbą odnośników warto postawić na pewne odchylenia w danych w zamian za automatyzację oraz przyspieszenie działań.
Szef wszystkich szefów. Na jego głowie leży zarządzanie "kreatywnym zamieszaniem" jakim jest Netim. Optymalizacja czasu pracy i nadanie priorytetów zadaniom to główna idea przyświecająca Pawłowi. Z zamiłowania piłkarz.
Pani Marysiu mówi się weganka nie wegetarianka (patrz opis autora). Wpis ok, szczególnie ta ostatnia wtyczka jest przeze mnie często używana. Następny wpis mógłby być o bardziej zaawansowanym zastosowaniu scrapebox
Panie Damianie, temat z pewnością będzie kontynuowany, jednakże branża SEO dostarcza wielu tematów, o których warto napisać, więc ciężko powiedzieć kiedy to nastąpi. Odnośnie moich upodobań kulinarnych, zapewniam Pana, że jestem wegetarianką – polecam wyszukać w Google artykuły na temat różnic między obiema dietami.
Scrapebox w mojej opinii jest narzędziem, które jako pierwsze powinno zostać zakupione przez SEO-wca. Bez względu na to, że masz na świecie złą opinię, jest doskonałym narzędziem wielofunkcyjnym. Zła opinia została wyrobiona przez ludzi, który nie potrafią docenić innych właściwości niż masowe komentarze. Ich strata…W kontekście zarządzania wielotysięcznymi danymi jest niezastąpiony. Jest to jedno z nielicznych narzędzi, które wykorzystuję do tej pory regularnie, w przeciwieństwie do dziesiątek innych, wiele droższych, które odeszły wraz z update-ami w zapomnienie.
Do artykułu dodałbym jeszcze opis płatnej wtyczki Automator. Świetna sprawa.
Zeby nie było samego słodzenia program nie jest wolny od wad. Checker proxy budzi do tej pory wiele wątpliwości w poprawności działania. Link Checker nie działa na stronach po https;// oraz brakuje mu obsługi wyrażeń regularnych. Ustawienie odstępów czasu między wykonaniem tylko do 60 sekund, w przypadku masowego sprawdzania PR banuje proxy po czasie. Tak poza tym to wszystko ok 🙂
Sporo osób z branży omija szerokim łukiem Scrapeboxa, ale może przez to, ze nie znają możliwości narzędzia, które na prawdę mogą ułatwić codzienną pracę. Część funkcjonalności SB można znaleźć w innych narzędziach, a z niektórymi zadaniami uporać się w zwykłym notatniku :), ale jednak fakt, że wszystko jest w jednym miejscu, sprawia, że zyskuje przewagę.
Faktycznie, narzędzie nie jest wolne od wad, jednakże przy działaniach na większą skalę niektóre błędy można moim zdaniem zaliczyć do „błędu statystycznego” – np. w Link Checker, czy podczas sprawdzanie indeksacji i w zamian za korzyści jakie otrzymujemy możemy przymknąć na nie oko.
Ja używam Scrapeboxa od zawsze i jestem w 100% zadowolony. Można go również do tej pory wykorzystywać do podlikowywania innych wpisów, oczywiście po wcześniejszej obróbce znalezionych miejscówek 🙂 Generalnie program, z typu „must have” dla każdego pozycjonera.
Scrapebox to raczej podstawa przy wielu działaniach i czasem mdło się robi jak wszyscy piszą oficjalnie, że jest be, a sami nim spamują na potęgę. To hipokryzja jest zła, a sb to to narzędzie jak każde inne 🙂
Wpis bardzo fajny jeśli ktoś zaczyna pracę z programem 🙂
Dzięki za artykuł. Wprawdzie pozycjonowaniem na zewnątrz zajmuje się wyłącznie na własne potrzeby to chyba pobawię się tym narzędziem. Tak ostrożnie oczywiście:)
Hej, co do opisywania harvestu dodaj info o używaniu custom footprintów 🙂
[…] Więcej o Scrapeboxie możecie przeczytaj tutaj: Scrapebox – pomoc w codziennych obowiązkach pozycjonera. […]
Fajny wpis, w sumie nie byłem świadomy za bardzo o istnieniu takich narzędzi, kiedy nie przeczytałem na znanym portal , że ktoś sprzeda informację o 500 sprawdzonych blogach do których można dodać swoje wpisy przy pomocy scrapboxa.
dzięki za obszerny opis, przymierzam się do pracy z tym programem i każdy poradnik będzie bardzo pomocny
Ciekawe narzędzie – polecane nawet przez Neila Patela na Quicksprout. Artykuł z bardzo konkretnymi informacjami. Dzięki 🙂