
W poprzedniej części przedstawiłam prostą instrukcję, jak sprawdzić poprawność wdrożenia consent mode w witrynie. To sposób, który nie wymaga dużego przygotowania czy znajomości języków programowania. Jest on jednak dość ogólnikowy i dla dociekliwych może być niewystarczający. Ponadto metoda ta nie dostarcza dokładnych informacji o charakterze zbierania danych i sposobie ich przetwarzania. Przyjrzymy się zatem nieco innemu, dokładniejszemu sposobowi weryfikacji poprawności wdrożenia consent mode.
Czy consent mode działa – metoda dla deweloperów
Wbrew zaproponowanej nazwie, z metody tej może skorzystać każdy. Właściwie jest ona nawet prostsza pod względem przygotowania technicznego – nie trzeba korzystać w niej z dodatkowych narzędzi, jak wspomniane w poprzedniej części usługi Google (Tag Assistant, Tag Manager itp.). Wystarczy jedynie:
- wejść do przeglądarki w trybie incognito (lub po wyczyszczeniu danych przeglądania)
- skorzystać z narzędzi dla deweloperów.
Ten drugi krok może brzmieć tajemniczo, ale zostańcie ze mną – to naprawdę nie jest skomplikowane.
- Czyścimy dane przeglądania w przeglądarce: opcje Chrome – wyczyść dane przeglądania
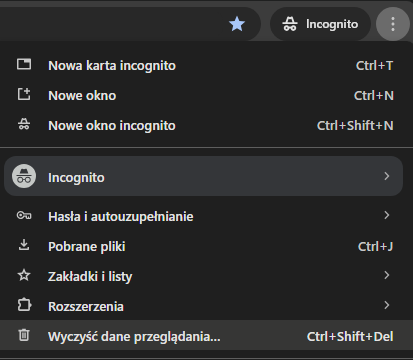
- W ekranie przeglądarki, zanim przejdziemy do witryny, klikamy prawym przyciskiem myszki i wybieramy opcję „Zbadaj”
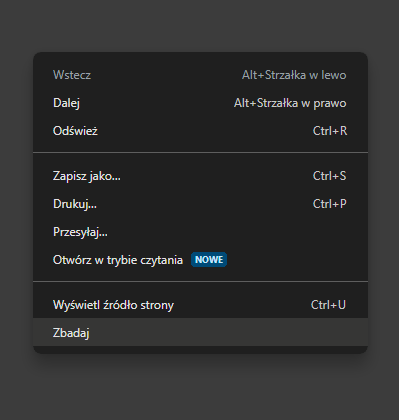
- Przechodzimy na kartę Network
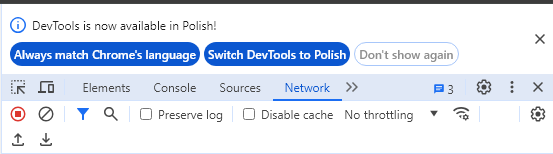
- Teraz możemy otworzyć stronę, którą chcemy sprawdzić. Jeszcze nie klikajmy żadnych zgód na banerze. W filtrze narzędzi dla deweloperów wpisujemy „gcd”
5. Następnie zaznaczamy pierwsze zdarzenie „collect” i wybieramy w nowym polu kartę Payload (Ładunek)
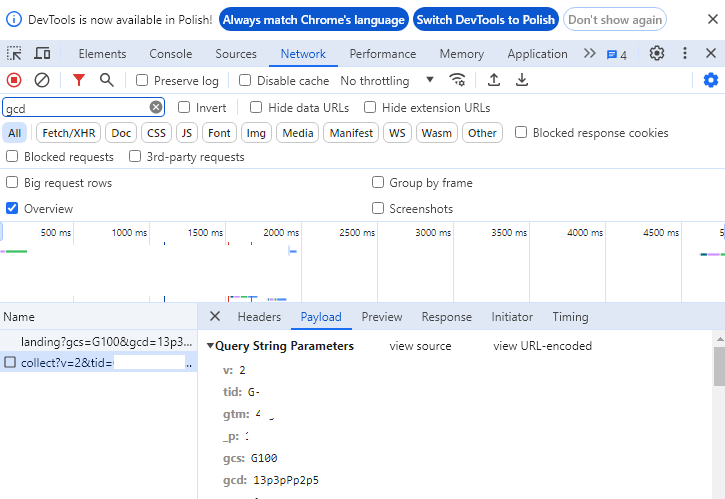
Jesteśmy razem? Dobrze, to teraz wyjaśnijmy sobie, co widzimy.
Parametr gcs i gcd to parametry tagu Google, które odpowiadają za przekazanie Google statusu zgody. Status zgody automatycznie powinien być „brakiem zgody”, tzn. dopóki użytkownik nie potwierdzi na banerze swojej zgody na zbieranie i przetwarzanie danych (a dane te powinny być podzielone na różne kategorie, zależnie od celów, w jakim są zbierane i przetwarzane – o tym za chwilę).
Jakie statusy zgody przekazujemy do Google?
W całym zamieszaniu z consent mode chodzi o doprecyzowanie rodzajów zgód, jakich użytkownik powinien udzielić wchodząc na dowolną stronę.
Do tej pory istniały dwa statusy zgód przekazywane przez kod śledzący:
- zgoda analityczna (analytics_storage)
- zgoda na pomiar skuteczności (ad_storage)
Z consent mode konieczne jest uzupełnienie kodu śledzącego o kolejne dwa statusy:
- zgoda na wykorzystywanie danych użytkownika przez Google do celów reklamowych (ad_user_data)
- zgoda na reklamę spersonalizowaną (ad_personalization)
Pierwsze dwie zgody opisuje parametr gcs. Po sprawdzeniu przez narzędzia analityczne tego parametru możemy zobaczyć różne odczyty zaczynające się literą G i ciągiem cyfr (jedynek i/lub zer).
| Zapis parametru gcs | ad_storage | analytics_storage |
| G100 | odmowa | odmowa |
| G101 | odmowa | zgoda |
| G110 | zgoda | odmowa |
| G111 | zgoda | zgoda |
| G1- | zgoda nie jest wymagana | zgoda nie jest wymagana |
Po aktualizacji consent mode to nie wystarczy, dlatego mówimy o v2 (drugiej wersji) tego rozwiązania. Dochodzi nam tutaj parametr gcd, definiujący dwa pozostałe statusy zgód. W tym parametrze możemy zobaczyć najpierw wartości domyślne (a domyślną opcją powinien być brak zgody na cele reklamowe i personalizację), następnie możemy sprawdzić wartość po wyrażeniu zgody na część lub wszystkie możliwości zbierania i przekazywania danych.
Tutaj parametr definiowany jest wartościami wyrażonymi małymi literami. Co oznaczają poszczególne wartości?
| litera | Status domyślny | Status po zmianie |
| l (małe L) | brak consent mode | brak consent mode |
| m | brak statusu domyślnego | odmowa |
| n | brak statusu domyślnego | zgoda |
| p | odmowa | brak zmiany |
| q | odmowa | odmowa |
| r | odmowa | zgoda |
| t | zgoda | brak zmiany |
| u | zgoda | odmowa |
| v | zgoda | zgoda |
W idealnie wdrożonym consent mode w wersji 2 powinniśmy zatem w parametrze gcd zobaczyć przed wyrażeniem zgody wartości:
- gcs=100 – domyślnie odmowa na pierwsze dwa statusy zgód
- gcd=11p1p1p1p5 – wszystkie cztery zgody są domyślnie odrzucone
Kolejność parametrów w tym opisie to:
11(ad_storage)1(analytics_storage)1(ad_user)1(ad_personalization)5
Po wyrażeniu zgód przez użytkownika możemy natomiast zobaczyć, jak w naszym przykładzie:
gcd=13q3rPq2q5 – czyli kolejno: odmowa przed aktualizacją i po niej, odmowa przed aktualizacją i zgoda po aktualizacji i w pozostałych dwóch statusach odmowa przed aktualizacją i po niej.
Oznacza to, że użytkownik wyraził zgodę jedynie na zbieranie danych służących pomiarowi skuteczności (analytics_storage).
Prawidłowe ustawienia consent mode w wersji drugiej sygnalizuje użycie liter p, q, r. Jeśli widzimy inne literki, oznacza to problemy:
- małe l – brak konfiguracji trybu zgody lub tryb zgody niezaktualizowany do wersji drugiej (jeśli małe l występuje w dwóch ostatnich statusach)
- małe t, u lub v – na naszej witrynie jest skonfigurowana domyślna zgoda, co jest niezgodne z nowym standardem
- małe m, n – nie mamy skonfigurowanego domyślnego stanu zgody
Właśnie dlatego ta metoda jest dokładniejsza – możemy dzięki niej wyłapać problemy i określić ich charakter. Na wielu witrynach consent mode jest wdrażane integracjami, wtyczkami czy w pierwszej wersji. Skorzystanie z Tag Assistanta pozwoli nam jedynie sprawdzić, czy przesyłanie danych wywołuje się przed i po wyrażeniu zgody, jednak w razie problemów nie da nam tylu szczegółowych informacji.
Dlaczego jest to tak istotne?
Domyślnie wyrażona zgoda lub brak konfiguracji mogą z czasem wprowadzić ogromne zamieszanie w danych o ruchu. Obserwujemy chociażby takie problemy w witrynach:
- błędne przypisywanie ruchu do kanału direct/referral w Analytics
- spadek liczby konwersji w kampaniach Google Ads
- wahania w danych o ruchu w witrynie
I jakkolwiek od pewnego czasu coraz wyraźniej zarysowuje się konieczność pracowania raczej na trendach i zbiorach niż na konkretnych liczbach, to jednak jakość i liczba danych tworzących trendy i zbiory ma ogromne znaczenie. Bez nich machine learning nie ma możliwości rozwoju w postaci kampanii reklamowych przynoszących zwrot.
Pozostaje oczywiście modelowanie konwersji (niezbędne, bo przecież część użytkowników świadomie nie wyraża zgody na zbieranie danych), jednak jeśli pracujemy na zaburzonych danych modelowanie również będzie nieprawidłowe – lub nie zadziała z braku wystarczającej liczby danych.
Z branżą SEM związana od niemal 10 lat. Pierwsze kroki w świecie digital marketingu stawiała w SEO i content marketingu, stopniowo przesuwając zainteresowania w stronę PPC. Stawia na wydajność i rentowność prowadzonych działań, szuka rozwiązań dopasowanych do specyfiki projektu. Uwielbia rozmowy z ludźmi, dobrą lekturę, muzykowanie i dziewiarstwo ręczne.