
Audytując treści blogowe serwisu, warto zagłębić się również w kwestie techniczne – które w prosty sposób możemy wyciągnąć ze Screaming Froga. Zwykle nie ma z tym problemu w sytuacji, gdy mamy do czynienia z małym serwisem. Gorzej, gdy nasza strona jest na przykład sklepem internetowym posiadającym tysiące produktów. Jak zawęzić wykonanie crawla, aby efektywnie wyciągnąć dane jedynie z sekcji bloga?
Spis treści
Konstrukcja serwisu
Zacznijmy jednak od rozważenia przypadków, jakie mogą nas spotkać. Istnieją de facto 2 sytuacje, z którymi możemy mieć do czynienia:
Wydzielony katalog w URL bloga
Przy sprzyjających warunkach nasz blog będzie miał ustaloną konstrukcję adresu URL. Oznacza to, że w adresie każdego artykułu blogowego znajdziemy stały katalog, po którym możemy w prosty sposób zawęzić działania naszego crawla.
Może to być np.:
- nazwa-serwisu.pl/blog/tytul-artykulu/
- nazwa-serwisu.pl/post/tytul-artykulu/
itd.
Brak wydzielonego katalogu w URL bloga
W przypadku wielu stron jednak nie jest to takie proste.
Bardzo często strony, np. stojące na WordPressie (najpopularniejszym CMS w Internecie), nie mają wydzielonego katalogu w URL, a ich konstrukcja adresów URL wygląda tak: nazwa-serwisu.pl/tytul-artykulu/.
W takim przypadku zmuszeni jesteśmy do nieco większego kombinowania, ale bez obaw – nie wszystko stracone.
Zawężenie do katalogu
Jeśli nasze artykuły blogowe mają w ścieżce URL podany katalog, to wystarczy, że w Screaming Frogu podamy dokładnie taką ścieżkę, a następnie zmienimy domyślne analizowanie całej subdomeny na subfolder.
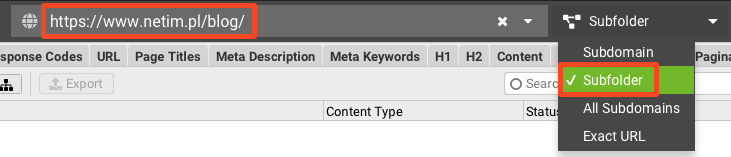
Filtrowanie URL za pomocą wyrażeń regularnych
Jeżeli nasz serwis posiada wydzielony katalog, lub inny element powtarzalny w URL wpisów blogowych, to możemy skorzystać z wyrażeń regularnych. Potrzebujemy stałego elementu, który jest charakterystyczny dla danej sekcji – w tym przypadku artykułów blogowych.
Świetnym przykładem do zastosowania wyrażeń regularnych są zwykle sklepy stojące na CMS IdoSell. Domyślne adresy URL w sekcji blogowej mają tam dopisek, który odróżnia je od reszty serwisu. W zależności od końcowej konfiguracji może mieć to różną formę, jednak sprawdziłem dwa przykładowe sklepy stojące na tym CMS i w obu widzimy podobny dopisek:
- https://foodsbyann.com/Nie-tylko-apteczka-na-wakacje-Co-jeszcze-moze-Ci-sie-przydac-na-urlopie-blog-pol-1724154430.html
- https://www.denley.pl/Jak-dobrac-spodnie-do-marynarki-cinfo-pol-1434.html
Pogrubieniem zaznaczyłem fragment, który mam na myśli. Są to kolejno “-blog-pol-” oraz “-cinfo-pol-”. Jak w takim razie skonfigurować crawla, aby dostać w wynikach wyłącznie wpisy blogowe z serwisu foodsbyann.com?
W Screaming Frogu klikamy w ustawienia Configuration -> Include.
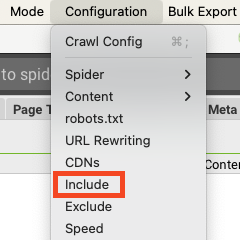
W tej zakładce możemy ustawić reguły, które będą bezwzględnie przestrzegane w crawlu. Całość działa w oparciu o regex, ale jeśli go nie znasz, to się nie przejmuj – ChatGPT świetnie sobie z nim radzi i z pewnością Ci pomoże.
Klikamy w pole tekstowe i podajemy regułę – w naszym przypadku, aby wszystkie adresy URL zawierały w sobie fragment “-blog-pol-”.
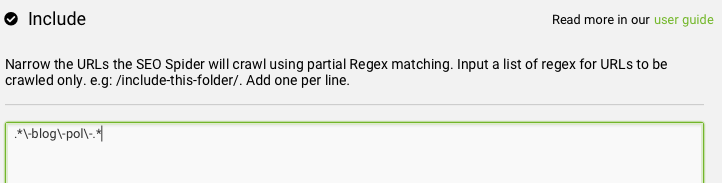
Pod polem tekstowym mamy możliwość przetestowania wybranych przez nas adresów URL, aby sprawdzić, czy reguła działa prawidłowo.
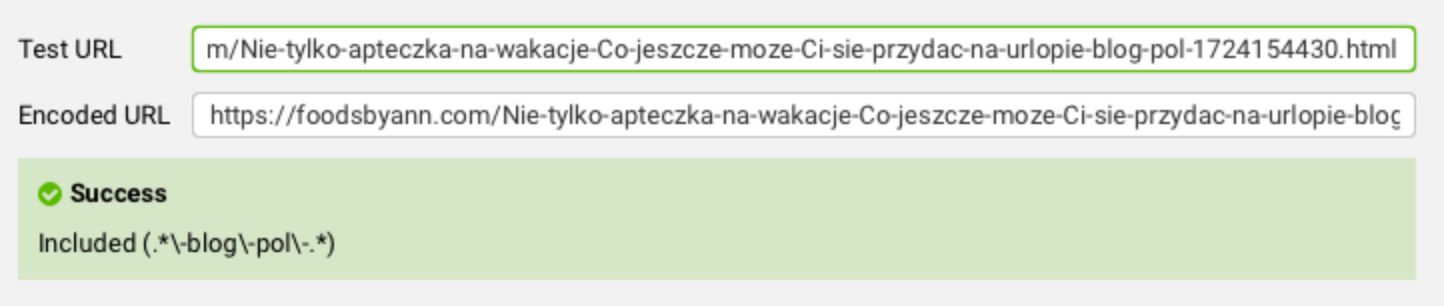

Jak widać, nasza reguła działa. Klikamy „Ok”, aby zapisać ustawienia i uruchamiamy crawl.
Crawl po mapie witryny xml
Screaming Frog ma wbudowaną możliwość wykonywania crawli na podstawie przesłanej mu mapy witryny w formacie XML. Jeżeli nasz serwis posiada dedykowaną mapę dla treści blogowych, to możemy ją tutaj wykorzystać.
W tym celu należy przejść do trybu „List”.
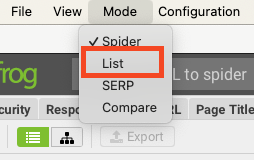
W tym trybie Screaming Frog ogranicza się wyłącznie do podanych przez nas adresów – nie podąża za linkami, analizując zawartość całego serwisu tak jak w trybie Spider.
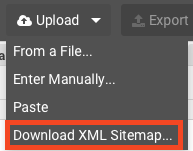
Klikamy Upload, a następnie wybieramy Download XML Sitemap.
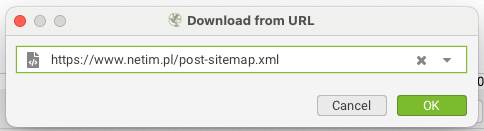
W wyskakującym oknie podajemy adres naszej mapy witryny – musimy pamiętać, aby podać mapę zawężoną do artykułów blogowych.
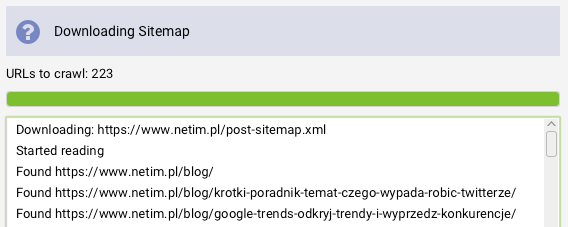
Po kliknięciu przycisku „Ok” Screaming Frog automatycznie pobierze adresy URL występujące w naszej sitemapie. Jeżeli adresy będą nam odpowiadać, wystarczy, że ponownie naciśniemy „Ok”, aby narzędzie wykonało crawl.
Tu jednak mała uwaga. W zależności od sposobu generowania sitemapy możemy uzyskać nieco różne efekty.
Przykładowo, Yoast SEO w swojej mapie XML dla wpisów blogowych ma również linki do zdjęć, które w nich występują. Dlatego po pobraniu adresów z linku wygenerowanego przez to narzędzie zobaczymy sporo adresów zbędnych z naszej perspektywy. Co należy zrobić w takiej sytuacji? Wystarczy, że wykluczymy je w ustawieniach.
Przechodzimy do Configuration -> Exclude. W wyskakującym oknie znajdziemy duże pole tekstowe, w którym możemy wpisywać reguły blokujące konkretne zasoby. W moim przypadku wystarczy prosta reguła:

W ten sposób możemy wykluczyć także strony paginacji, kategorii itp.
Klikamy „Ok”, aby zapisać i uruchamiamy crawl.
Elementy powtarzalne dla bloga
Gdy poprzednie metody zawiodą, zostaje nam jeszcze wykorzystanie dwóch wbudowanych w Screaming Frog funkcji:
- Custom Search – służy do szybkiego przeszukiwania stron pod kątem określonych fraz lub elementów kodów.
- Custom Extraction – bardziej zaawansowana wersja, dzięki której wyodrębnimy specyficzne elementy kodu HTML.
Dzięki nim możemy wyszukiwać specyficzne elementy w analizowanym serwisie. Niestety jednak to rozwiązanie nie ograniczy nam na starcie crawlu. Konieczne będzie wykonanie pełnej analizy strony i dopiero później będziemy mogli zawęzić wyniki do adresów spełniających nasze kryteria.
Na starcie jednak musimy znaleźć element w wyglądzie lub w kodzie strony, który będzie odrębny dla artykułów blogowych. Najczęściej będą to:
- określone frazy np. „Blog” w Breadcrumbs,
- sekcja komentarzy,
- klasy i identyfikatory div np. <div class=”blog-post”>,
- nazwa autora,
- data publikacji,
- tagi Open Graph.
Po określeniu takiego kryterium przechodzimy do odpowiedniej zakładki, czyli Configuration -> Custom i wybieramy Custom Search bądź Custom Extraction w zależności od naszych potrzeb.
W przypadku naszego bloga jako element charakterystyczny wskażemy sobie tekst „Podobne wpisy”. Taka treść występuje wyłącznie w artykułach blogowych i jest dodawana automatycznie w każdym tekście – mam więc pewność, że nie pominę żadnego artykułu.
Do tak prostego kryterium wystarczy użycie Custom Search. Jego konfiguracja wygląda następująco:
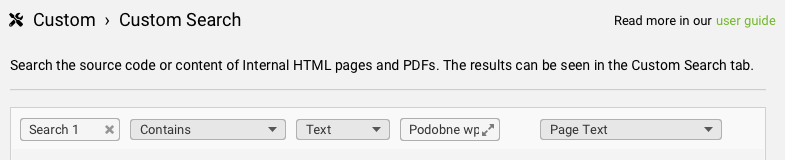
Klikam „Ok”, a następnie wykonuję crawl serwisu.
Efekty naszego Custom Search są widoczne w dedykowanej zakładce, którą musimy wybrać z listy pod polem do wpisywania URL.
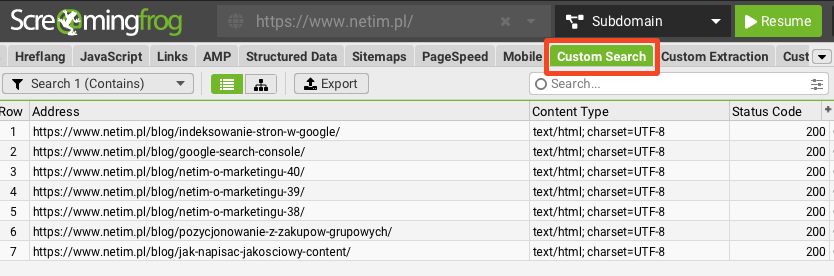
Przekrojowo przeszliśmy przez główne funkcje, z których ja korzystam do zawężania crawla Screaming Froga wyłącznie do sekcji blogowej. Jeżeli znacie inne, to śmiało podzielcie się nimi w komentarzach 😉
Specjalista SEO, dla którego praca stała się pasją. Zawsze na bieżąco z najnowszymi trendami, z zamiłowaniem do testowania nowych narzędzi. Ceni innowacyjność i nieustannie dąży do doskonalenia swoich umiejętności. Poza biurem, jest zapalonym fanem sportu, ze szczególnym uwzględnieniem angielskiej Premier League.