
Duplikacja treści to problem, który dotyczy wielu witryn. Często wynika on z niewiedzy i nieświadomości właścicieli stron, przez co zmagają się oni z problemem osiągnięcia zadowalających pozycji w wynikach wyszukiwania, a także ograniczeniem widoczności witryny.
Jeśli natrafiłeś w swoim serwisie na wyglądające identycznie podstrony z taką samą treścią, znajdujące się pod różnymi adresami URL, lub dodajesz do wizytówek, katalogów i porównywarek produktów treści skopiowane ze swojej strony – to z pewnością jednym z problemów występujących w Twojej witrynie jest duplikacja treści. Czym jest duplicate content? Jakie powoduje problemy oraz jak sobie z nim radzić? O tym w dalszej części wpisu.
Spis treści
Czym jest duplikacja treści
Duplikacja treści, czyli duplicate content to powielenie tej samej treści pod więcej niż jednym adresem URL w obrębie danej domeny lub kilku domen. Często jesteśmy nieświadomi istniejącego problemu, gdyż duplikacja jest efektem nie tylko kopiowania treści. Źródłem problemu może być zaniedbanie wielu kwestii technicznych np. brak przekierowań lub niewyłączenie z indeksacji testowej wersji witryny. Warto upewnić się, czy treść w serwisie jest unikalna, ponieważ to tylko nieliczne z przykładów mogące powodować kopie.
Algorytmy Google doskonale radzą sobie z identyfikacją stron zawierających niskiej jakości content. Aby dostarczyć użytkownikowi jak najbardziej trafnej odpowiedzi — na wysokich pozycjach będą wyświetlane witryny mogące pochwalić się unikatowymi treściami, dogłębnie wyjaśniającymi dany temat. Dlatego tak istotne jest dbanie o zamieszczanie w swojej witrynie oryginalnego contentu, dostarczającego wartość dla użytkownika.
Duplikacja wewnętrzna i zewnętrzna – jakie powodują problemy?
Jak wspomniałam wcześniej, duplikacja treści może dotyczyć jednej lub kilku witryn. Z tego względu wyróżniamy duplikację wewnętrzną oraz duplikację zewnętrzną.
Duplikacja wewnętrzna
Duplikacja wewnętrzna to powielenie tej samej treści pod różnymi adresami URL w obrębie jednego serwisu. Jedną z konsekwencji tego działania może być kanibalizacja słów kluczowych. Jest to sytuacja, w której na to samo słowo kluczowe wyświetlają się przynajmniej dwie podstrony tej samej domeny. Prowadzi to do niestabilnych pozycji w wynikach wyszukiwania. Algorytm Google na dane zapytanie użytkownika może wyświetlać jedną z podstron, a kolejnym razem wyświetlony zostanie inny adres URL na niższych pozycjach. Długofalowo może to doprowadzić do trwałych spadków w wynikach wyszukiwania.
Duplikacja zewnętrzna
Duplikacja zewnętrzna to kopie treści występujące w różnych serwisach. Sytuacja ma miejsce, gdy serwisy zewnętrzne „zapożyczą” tekst z naszej witryny lub gdy samodzielnie zamieścimy skopiowany z własnej strony tekst w zewnętrznych domenach – katalogach, serwisach sprzedażowych np. Allegro, czy porównywarkach typu CENEO. Przykładem duplikacji zewnętrznej jest także powielenie strony np. w subdomenie. Zagrożenie, jakie niosą takie działania, również wiążą się z ograniczeniem widoczności witryny w wynikach wyszukiwania. W przypadku zduplikowanych treści w kliku domenach Google wyświetli na wyższych pozycjach stronę, która ma większy autorytet, prowadzi do niej więcej linków, jest lepiej zoptymalizowana lub ma długą historię, czyli jest starszą domeną.
Przyczyny duplikacji wewnętrznej
Przyczyn powstania duplikacji wewnętrznej można wymieniać bardzo wiele. W zależności od złożoności technicznej serwisu, ich wyeliminowanie może być łatwiejszym lub trudniejszym zadaniem. W tej części wpisu omówione zostały najczęstsze problemy z duplikacją wewnętrzną, które można spotkać w witrynach internetowych.
Powielenie tego samego produktu pod różnymi adresami URL
Różne warianty tego samego produktu znajdujące się na osobnych podstronach to bardzo częste rozwiązanie stosowane w e-commerce. Nie byłoby ono problematyczne, gdyby opis dla każdego wariantu produktu był unikalny. Niestety w większości przypadków treść pozostaje ta sama, powodując duplikację. Nic w tym dziwnego – bardzo czasochłonnym zadaniem byłoby stworzenie unikalnego opisu dla danego modelu butów sportowych, które występują w 16 różnych kolorach lub napisanie oryginalnych opisów dla taśmy izolacyjnej występującej w kilku różnych szerokościach.
Jak poradzić sobie z problemem duplikacji treści?
Jeśli nie mamy możliwości stworzenia unikalnych opisów – jednym z prostszych rozwiązań jest zastosowanie tagu rel=canonical prowadzącego do wersji podstawowej produktu. Link kanoniczny służy do wskazania robotom wyszukiwarki preferowanej strony kanonicznej dla jednakowych lub bardzo podobnych podstron. Wykorzystywany jest w sytuacjach powtarzania się tej samej treści pod różnymi adresami URL. To rozwiązanie zostało zastosowane m.in. na stronie notino.pl. Wybór pojemności wody toaletowej powoduje zmianę adresu URL. Na każdej podstronie wariantu wdrożono jednak link kanoniczny prowadzący do podstawowej strony produktu.
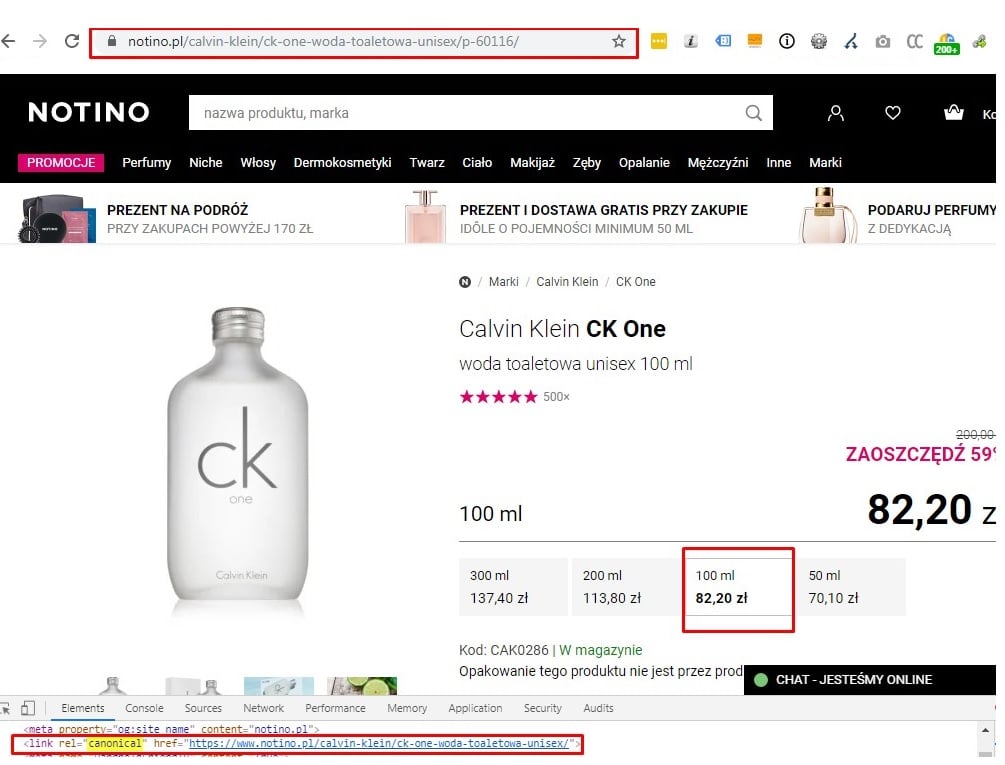
Alternatywnym sposobem na pozbycie się duplikacji będzie stworzenie jednej, unikalnej karty produktu wraz z możliwością wyboru konkretnego wariantu. Ważne jednak, aby wybór wersji produktu nie powodował zmiany adresu URL. Wszystkie pozostałe podstrony produktu powinniśmy przekierować na stronę podstawową.
W sytuacji, gdy zależy nam na frazach związanych z danym wariantem oferowanego artykułu, rozwiązaniem jest przygotowanie unikalnych podstron dla wszystkich jego wersji. Każdy z produktów należy opatrzyć oryginalną treścią i w ten sposób zoptymalizować pod szczegółowe frazy związane z wyróżniającą go cechą. Dzięki temu możemy zwiększyć widoczność serwisu na frazy z długiego ogona, a tym samym zyskać konwertujący ruch na stronie. Osoby wpisujące w oknie wyszukiwarki frazy szczegółowe, dokładnie wiedzą czego szukają. Gdy trafią na stronę z poszukiwanym produktem – szansa na dokonanie przez nich zakupu zwiększa się. Przykładem serwisu tworzącego osobne opisy dla różnych wersji produktu jest galeriamarek.pl.

Strona dostępna pod wieloma adresami
Istnieje wiele przyczyn wyświetlania się w wynikach wyszukiwania danej witryny pod wieloma adresami URL. Jakie są najczęstsze powody pojawienie się kopii serwisu?
- Indeksowanie wersji testowej witryny
Tworzeniu nowej witryny internetowej lub zmianie istniejącej towarzyszy najczęściej pojawienie się wersji testowej strony, która powinna być dostępna wyłącznie dla zainteresowanych osób. Po uruchomieniu oryginalnej wersji serwisu strona testowa będzie stanowiła kopię. Dlatego tak ważne jest zablokowanie deweloperskiej wersji strony przed indeksacją strony w google. Można to wykonać poprzez wykorzystanie metatagu „noindex” lub wprowadzenie w pliku robots.txt odpowiedniej dyrektywy.
- Wyświetlanie się strony głównej pod wieloma adresami
Niektóre systemy CMS powodują powstawanie kilku wersji adresów URL, pod jakimi aktywny jest serwis np. adres ze „ / ”na końcu i bez, wersja z „www” i bez „www”, adresy z parametrami „index.html”, „index.php” i bez. Oznacza to, że pod kilkoma adresami URL widoczna jest ta sama zawartość np.:
- http://domena.pl/
- http://domena.pl
- http://www.domena.pl
- http://www.domena.pl/index.html
- http:// domena.pl/index.html
- http://domena.pl/index.php
- http://www.domena.pl/index.php
Dla właściwego adresu strony, jakim jest – http://domena.pl wszystkie powyższe adresy wywołują duplikację. Aby wskazać robotom wyszukiwarki podstawową wersję strony, powinniśmy przekierować na nią wszystkie pozostałe adresy stanowiące kopie.
- Nieprawidłowe wdrożenie certyfikatu SSL
Komplikacje związane z duplikacją treści mogą powodować również nieprawidłowe przekierowania lub brak przekierowań przy wdrożeniu certyfikatu SSL. Strona z protokołem https i bez tego protokołu to dwa różne adresy URL, a tym samym dla robotów wyszukiwarek dwie różne wersje tej samej witryny. Aby nie doprowadzić do duplikacji treści, należy:
- wykonać prawidłowe przekierowania 301 – jeden do jednego, z wersji http na https dla każdej podstrony serwisu;
- upewnić się, czy w linkowaniu wewnętrznym nie ma żadnych adresów prowadzących do wersji witryny bez http, w tym celu sprawdźmy linki kanoniczne, pliki graficzne, hiperłącza – warto też podmienić w mirę możliwości linki zewnętrzne na prowadzące do właściwej wersji serwisu;
- zaktualizować sitemap.xml poprzez wygenerowanie nowego pliku z aktualnymi adresami URL;
- zweryfikować w narzędziu Google Search Console nową usługę dla wersji witryny ze wdrożonym protokołem https i przesłać zaktualizowany plik sitemap.xml.
Więcej przeczytasz o tym w naszym artykule: Co oznacza błąd połączenia SSL i jak go naprawić?
Niezoptymalizowane strony sortowania i filtrowania
Jedną przyczyn powodującą duplikację jest nieprawidłowo zoptymalizowana funkcja sortowania i filtrowania na stronie. To również jeden z problemów często spotykany w e-commerce. Należy pamiętać, że sortowanie i filtrowanie zmieniają jedynie układ wyświetlania produktów, zawartość jednak pozostaje ta sama.
W niektórych sklepach internetowych można spotkać się z rozwiązaniem, gdzie funkcja sortowania lub filtrowania nie powoduje zmiany adresu URL, lub zostaje dodany parametr po hasztagu – takie podstrony nie są wówczas indeksowane. Jest to dobry sposób na uniknięcie duplikacji. Natomiast gdy podczas sortowania lub filtrowania produktów strona zostaje przeładowana i zmienia się adres URL (zostaje dodany parametr), powstają kopie podstawowej wersji strony.
Jak rozwiązać problemem kopii treści?
Najłatwiej zastosować na duplikujących się podstronach tag rel=canonical prowadzący do jej oryginalnej wersji – strony filtracji i sortowania jednak nadal mogą być wyświetlane w serpach. Jeśli chcemy pozbyć się ich z indeksu, rozwiązaniem jest zastosowanie metatagu „noindex”, dzięki temu nie będą dostępne dla użytkowników z poziomu wyników wyszukiwania.
Innym sposobem jest zablokowanie indeksacji podstron sortowania i filtrowania w pliku robots.txt. Zastosowanie komendy blokującej robotom wyszukiwarki dostęp do danych typów podstron pozwala zaoszczędzić crawl budget.
Przed wdrożeniem powyższych rozwiązań warto jednak przeanalizować, jak dużo jest wejść na te typy podstron, aby przypadkowo nie „ucinać” wartościowego ruchu na stronie. Jeśli istnieje taka możliwość, warto zoptymalizować złożenia filtrów pod szczegółowe słowa kluczowe, które mają potencjał i tym samym generować ruch na stronie z fraz z długiego ogona. Przykładem jest strona Zalando. Dla kategorii „sukienki” – strony filtrowania po kolorach optymalizowane są pod konkretne złożenia np. „czerwona sukienka”. Na każdej podstronie znajduje się również obszerny opis nasycony kluczowymi frazami.

Wewnętrzna wyszukiwarka i kopie
Problemy z duplikacją może powodować także wewnętrzna wyszukiwarka w serwisie. Korzystanie z niej w większości przypadków powoduje wygenerowanie nowej podstrony. Tworzy to duplikaty dla już istniejących podstron zoptymalizowanych pod wyszukiwane hasło. Sposobem na pozbycie się problemu jest dodanie w pliku robots.txt komend blokujących robotom możliwość wejść na podstrony wewnętrznych wyszukań, tym samym zapobiegając ich indeksacji.
Niezoptymalizowane strony paginacji
Paginacja lub inaczej stronicowanie to kolejny element, dla którego niedopilnowanie odpowiedniej optymalizacji może doprowadzić do pojawiania się problemu duplikacji. Paginacja wykorzystywana jest do podzielenia zawartości danej strony na kilka części i zamieszczenia ich na osobnych podstronach. Najczęściej występuje na podstronach listy produktów, kategoriach i tagach agregujących wpisy blogowe oraz stronach dłuższych artykułów blogowych, których treść jest podzielona na kilka podstron. Jakie problemy powoduje źle wdrożone stronicowanie?
- Kopie treści na kolejnych podstronach paginacji
W przypadku paginacji najpowszechniejszym błędem powodującym duplikację jest wyświetlanie się na każdej kolejnej podstronie stronicowania tego samego opisu. Treść powinna pozostać jedynie na pierwszej stronie, a na kolejnych podstronach należy ją usunąć.
- Brak zróżnicowania znaczników title
Warto również zwrócić uwagę na prawidłową optymalizację znaczników title. Zazwyczaj dla kolejnych podstron paginacji ustawiane są automatycznie takie same tagi title. Aby uniknąć duplikacji tytułów stron, najlepiej rozróżnić je dodając dopisek np. „Strona 2”.
- Powielona pierwsza strona paginacji
Podczas wdrażania stronicowania zdarza się, że pierwsza strona dostępna jest pod dwoma różnymi adresami URL np.: stroną główną kategorii domena.pl/strona-kategorii oraz stroną z numeracją paginacji domena.pl/strona-kategorii -1. Pod tymi dwoma adresami znajduje się identyczna zawartość, co powoduje kopie. W tej sytuacji najlepiej usunąć z linkowania wewnętrznego duplikat strony kategorii i wykonać przekierowanie 301 na podstawowy adres strony.
Nieodpowiednie zarządzanie podstronami tagów
Brak odpowiedniej optymalizacji podstron tagów może doprowadzić do pojawienia się w serwisie kanibalizacji słów kluczowych. Podstrony tagów wpisów lub tagów produktów mogą konkurować na określone słowa kluczowe z właściwymi podstronami, które zoptymalizowane są pod dane frazy i które według naszego uznania stanowią większą wartość dla użytkowników. Zdarza się niestety, że algorytmy Google przewrotnie zamiast preferowanej przez nas strony wyświetlają w wynikach wyszukiwania podstronę tagów, często na dużo niższych pozycjach. Pojawienie się tego problemu to oznaka, że w witrynie istnieją podstrony, które stanowią w pewnym stopniu kopie tematów.
Aby zapobiec takiej sytuacji, należy dokładnie zarządzać podstronami tagów. Jeśli są to istotne strony, generujące ruch w witrynie, powinniśmy zoptymalizować je pod frazy niebędące konkurencją dla kluczowych podstron. W przeciwnym wypadku najlepiej je wyindeksować, stosując metatag „noindex” lub blokując w robots.txt. Natomiast w sytuacji, gdy już pojawiła się kanibalizacja najlepiej wykonać przekierowanie 301 strony tagów na stronę, która jest dla nas kluczowa.
Nieprawidłowe wdrożenie wersji językowych strony
W serwisach, które posiadają wersje językowe, częstym problemem jest duplicate content wynikający z braku tłumaczeń dla wersji obcojęzycznych. np. w wersji angielskiej tekst na stronie w całości lub częściowo jest opublikowany w języku polskim. Taka sytuacja powoduje problemy w witrynie i może być przyczyną spadków widoczności oraz prowadzić do sytuacji, gdy polskie frazy będą wyświetlały się dla obcojęzycznych adresów.
Jak uchronić się przed duplikacją treści?
Rozwiązaniem problemu jest jak najszybsze przetłumaczenie treści na język odpowiadający dla danego kraju. O tym, jak odpowiednio zarządzać witrynami multiregionalnymi i wielojęzycznymi można przeczytać w supporcie Google – https://support.google.com/webmasters/answer/182192?hl=pl&ref_topic=2370587.
Przy wdrożeniu wersji zagranicznych strony należy także pamiętać o poprawnym wprowadzeniu oznaczeń w kodzie strony, które będą informowały roboty wyszukiwarki, że witryna jest dostępna w kilku wersjach językowych. Metody wskazywania stron alternatywnych dokładnie zostały opisane w pomocy Google – https://support.google.com/webmasters/answer/189077.
Duplikacje strony w wersji desktopowej i przeznaczonej na urządzenia mobilne
W dobie Mobile-First Index posiadanie strony dostosowanej do wersji mobilnej jest koniecznością. Istnieje kilka technologii, które pozwalają na prawidłowe wyświetlanie strony na urządzeniach przenośnych. Ich implementacja wymaga zastosowania odpowiednich rozwiązań technicznych, które zapewnią prawidłową optymalizację pod kątem SEO, a także pozwolą zapobiec duplikacji treści.
- Wersja AMP strony
Standard AMP, czyli przyśpieszona strona mobilna to technologia stworzona głównie z myślą o sekcjach contentowych lub portalach informacyjnych, jednak jest stale rozwijana. Pozwala na poprawne wyświetlanie się strony na urządzeniach mobilnych. Jednocześnie umożliwia szybkie wczytywanie się strony, zwłaszcza wtedy, gdy użytkownik korzysta z sieci o wolnej transmisji danych.
Do wersji strony w standardzie AMP prowadzą osobne adresy URL np. – domena.pl/adres-url/amp/. Koniecznie jest więc dodanie w kodzie strony odpowiednich oznaczeń, które informują roboty o istnieniu wersji mobilnej strony.
Na podstronach, które są pełną wersją witryny, należy umieścić link prowadzący do odpowiadającej podstrony w standardzie AMP:
<link rel=”amphtml” href=”https://domena.pl/amp/”>
Na podstronach w standardzie AMP należy dodać tag kanoniczny prowadzący do odpowiadającej podstrony w pełnej wersji:
<link rel=”canonical” href=”https://domena.pl” />
- Wersja PWA strony
PWA, czyli Progressive Web App to technologia pozwalającą na tworzenie stron przeznaczonych na urządzenia mobilne, które wyglądają jak aplikacje. Nie ma tutaj jednak konieczności pobierania i instalowania aplikacji. Po wejściu na stronę, która korzysta z tego rozwiązania skrót aplikacji, można zapisać na pulpicie telefonu, a użytkownik może korzystać z niej nawet w trybie offline.
Przy tym rozwiązaniu technologicznym również należy pamiętać o wskazaniu oryginalnej wersji strony, aby uniknąć duplikacji treści. W tym celu na stronach progresywnej aplikacji internetowej powinniśmy zamieścić link kanoniczny prowadzący do oryginalnej wersji serwisu.
- Wersja strony „mobile”
Niektóre witryny posiadają osobną stronę w wersji mobilnej, która dostępna jest pod innym adresem URL. Zazwyczaj w adresie wersji mobilnej pojawia się przedrostek „m” lub „mobile” np. – m.domena.pl. Brak odpowiedniego zarządzania adresami podstron i zaniedbanie wprowadzenia odpowiednich oznaczeń w kodzie strony może prowadzić do pojawienia się duplikacji.
Prawidłowe wdrożenie wersji mobilnej wymaga wskazania robotom wyszukiwarki istniejących wersji witryny, implementując w kodzie strony poniższy zapis:
W wersji desktopowej w sekcji „head” należy wskazać alternatywny adres wersji mobilnej:
<link rel=”alternate” href=”https://m.domena.pl”>
W wersji mobilnej w sekcji „head” należy zamieścić link kanoniczny do wersji desktopowej:
<link rel=”canonical” href=”https://domena.pl” />
- Wersja RWD strony
Popularnym sposobem jest wdrożenie responsywnej wersji strony, która automatycznie dostosowuje się do rozdzielczości urządzenia, na jakim jest wyświetlana. To rozwiązanie nie powoduje problemów technicznych mogących wpływać na duplikację treści.
Duplikacja zewnętrzna – jak powstaje?
Duplikacja zewnętrzna może być efektem skopiowania treści z naszej witryny przez zewnętrzne serwisy. Często jednak nie zdajemy sobie sprawy, że w niektórych przypadkach samodzielnie doprowadzamy do powstania kopii. Przykłady takich działań zostały omówione poniżej.
Kopiowanie opisów produktów ze stron producenta
Bardzo często spotykaną praktyką w przypadku e-commerce jest zapożyczanie treść opisów produktów ze stron producentów. Po przejrzeniu witryn konkurencji możemy zauważyć, że większość z nich posiada ten sam opis produktów, również pochodzący od producenta. Efektem takich działań jest pojawienie się problemu duplikacji zewnętrznej w serwisie. Problem ten jest trudny do wyeliminowania, ponieważ stworzenie unikalnych opisów dla dziesiątek lub setek tysięcy produktów wiąże się z dużym nakładem pracy. Jak zatem poradzić sobie z problemem?
Warto przynajmniej dla priorytetowych produktów, generujących największą konwersję na stronie stworzyć oryginalne treści. Pozwoli to wyróżnić produkty spośród setek innych witryn oferujących te same artykuły, a także zbudować przewagę konkurencyjną.
Wdrożenie sekcji z komentarzami to najprostszy sposób wygenerowania unikalnego contentu na stronie. Użytkownicy pozostawiający opinie pod danym produktem w naturalny sposób rozbudowują treść na stronie.
Dobrym rozwiązaniem jest również zastosowanie boksów z polecanymi, powiązanymi produktami. Wzmocni to nie tylko linkowanie wewnętrzne w serwisie, ale w pewien sposób pozwoli również na wzbogacenie contentu na stronie. W celu pełnej optymalizacji w tym aspekcie polecamy skorzystać z usług z agencji content marketingowej.
Zamieszczanie opisów w porównywarkach cenowych i zewnętrznych serwisach sprzedażowych
Korzystanie z porównywarek cen oraz zamieszczanie oferty w zewnętrznych serwisach sprzedażowych również może się przyczyniać do powstania duplikacji zewnętrznej. Ma to miejsce, gdy wykorzystamy w tych witrynach te same opisy, które występują na naszej własnej stronie. Aby nie dopuścić do duplikacji treści, na potrzeby zewnętrznych serwisów można przygotować osobne opisy, które nie będą stanowiły kopii dla treści na stronie. W tym celu można również wykorzystać opisy producenta, pamiętając jednak aby sukcesywnie pracować nad unikalnością opisów w ramach własnej domeny.
Zamieszczanie wizytówek w katalogach firm
Analogicznym do powyższego przykładu, problemem z duplikacją zewnętrzną jest pozyskiwanie linków z katalogów stron. Korzystanie z tej metody linkbuildingu wiąże się z zamieszczeniem w tego typu serwisach krótkiego opisy firmy i świadczonych przez nią usług. Wielu właścicieli stron zamieszcza skopiowane informacje z własnej witryny, co powoduje powielenie opisu w dwóch różnych domenach. By ustrzec się przed duplikacją, wystarczy stworzyć unikalne opisy przeznaczone do publikacji w katalogach stron.
Tworzenie kilku podobnych lub takich samych serwisów
Przyczyną problemów z duplikacją może być również posiadanie kilku domen lub subdomen, na których znajduje się taka sama treść jak na domenie głównej. Przykładem może być przygotowanie witryn pod ofertę skierowaną dla danego miasta lub regionu. Właściciele stron, dla każdej lokalizacji tworzą osobne witryny, zamieszczając w nich opis oferty skopiowany z podstawowej domeny.
Niestety, takie mikrostrony szkodzą domenie główniej. Dla każdej domeny powinniśmy przygotować odrębne opisy, aby nie doprowadzić do powstania kopii. Rozwiązaniem jest również wykonanie przekierowania 301 z domen powielających treść, na domenę główną.
Kradzież treści z naszej strony
W pewnym przypadkach powielenie treści powstaje niezależnie od nas. Są to sytuacje, gdy ktoś skopiuje tekst z naszej strony i zamieści go w zewnętrznych domenach. Takie działania są niedopuszczalne, jednak nie zawsze jesteśmy w stanie się od tego uchronić. Nierzadko zdarza się, że takie działania nie są celowe, a wynikają raczej z niewiedzy. Dlatego warto skontaktować się z właścicielem witryny udostępniającym kopie tekstu z naszej strony, w celu wdrożenia na stronie duplikatu tagu rel=canonical wskazującego na oryginalną zawartość.
Podsumowanie
Z problemem duplikacji treści boryka się duża liczba witryn. Można wymieniać wiele przypadków powstania kopii. Nie na wszystkie zawsze mamy wpływ. Nie ma niestety jednoznacznej metody, która byłaby rozwiązaniem na pojawiający się problem. Nasze działania powinny przede wszystkim skupiać się na tworzeniu i zamieszczeniu w witrynie tylko oryginalnych i wartościowych treści. Ważne jest również systematyczne przeprowadzanie audytu strony, który pozwoli wykryć i wyeliminować ewentualne problemy z duplikacją.
Naszą redakcję tworzą eksperci marketingu internetowego: specjaliści SEO, SEM/PPC, social media i copywriterzy. Chętnie dzielimy się wiedzą – jeśli masz do nas pytania, zostaw je w komentarzu. Z przyjemnością na nie odpowiemy 🙂
[…] źródło: https://www.netim.pl/duplicate-content-na-czym-polega/ […]
Super opracowanie. Co do kradzieży to nie martwiłbym się zbyt mocno skopiowanymi treściami. Google może to po prostu traktować jako cytat i takie zachowanie (np. konkurencji) może przynieść nam paradoksalnie pożytek. Widać to w Google Search Console – linki do strony. Skopiowany paragraf z naszej strony nawet z lekkimi zmianami jest traktowany jako link do nas. Spotkałem się wiele razy z tym, że ktoś skopiował to czy tamto z mojego bloga ale celowo tego nie zgłaszam. W przypadku wyjątkowo „brutalnych” kopii stosuję raport DMCA. Konkretna podstrona jest usuwana z indeksu i cały serwis dostaję lekką karę praktycznie na zawsze.
Bardzo przydatny wpis. Miałem problem z duplikowaniem treści u siebie na stronie i szukałem rozwiązania. Dzięki za pomoc i pozdrawiam.
Bardzo przydatny artykuł 🙂 dzięki wielkie!